
Legibility Is the New Shelf Space: What Happens When AI Filters Food Before You See It
The shift from persuasion to proof is clear. The question is who captures value inside it.

Hey folks, thanks for being here!
In Issue #143 of Better Bioeconomy, I want to explore a question that keeps surfacing as I read about AI-mediated purchasing: what happens when AI agents start filtering food choices before consumers see a shortlist?
Most commentary on AI and food retail focuses on the final act: the autonomous grocery order. That story is real, but it is not yet mainstream. The part that is already at scale, and underexamined, is the filtering step.
Before AI buys food for you, it is already deciding what gets considered. The shift underneath is structural: value is migrating from persuasion to proof, and legibility, the ability to produce machine-readable evidence of what you claim, is becoming the new shelf space.
The optimistic version of this story says quality finally gets rewarded because machines can see it. I think the direction is right. But the distributional question keeps pulling me back. The proof economy has a monetisation layer, a definitional politics, and a cost floor that together determine who participates and who gets excluded. That is what I want to sit with in this piece.
Let’s dig in!
AI filtering is already reshaping what gets considered
The share of US shoppers using AI assistants jumped from 12% to 35% in a single year (Adyen 2026 Retail Report, Censuswide survey, n=2,000). The definition is broad and captures everything from product research to checkout delegation, but even accounting for that breadth, the year-on-year move signals a behavioural shift that has already happened.
The pattern extends beyond the US. A Deloitte Asia Pacific report found nearly three-quarters of consumers in the region already use AI to discover and compare products, and 29% of APAC consumer businesses have adopted agentic AI, a figure projected to reach 76% within two years. At GrabX 2026, Grab launched an AI shopping agent that builds a grocery cart from a photo or voice note, with smart substitutions across merchants, no item-by-item browsing required.
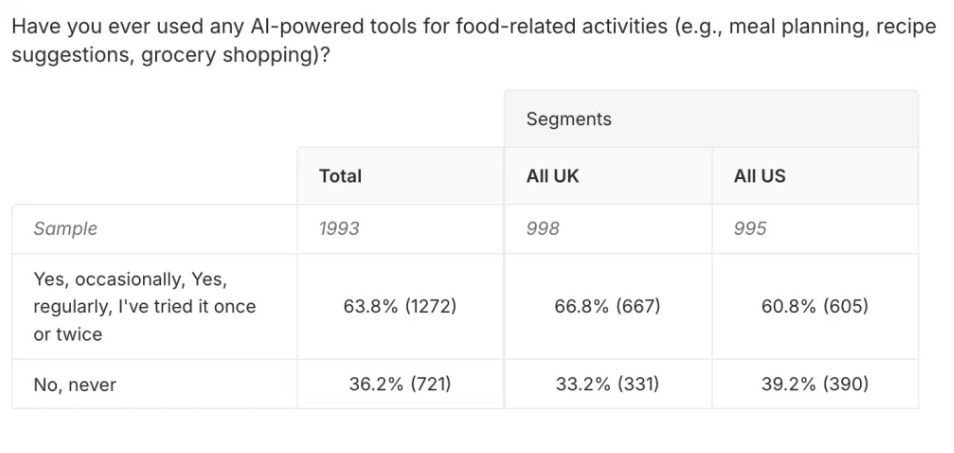
Most of that activity is filtering, however, not directly buying. A 2025 Attest survey found 63.8% of consumers had used AI tools for food-related activities, with the majority concentrated in recipe recommendations and meal planning rather than checkout delegation. And when researchers at Yale, Columbia, and the University of Chicago tested what happens to products inside agent-mediated selection (featured in Kantar’s “What Is Your AI Agent Buying?” analysis), they found a 20-40% reduction in selection probability when a key product attribute was missing from the structured data.
Autonomous AI purchasing, meanwhile, remains structurally constrained. A Bluestone PIM survey from March 2026 found 73% of consumers uncomfortable with AI completing purchases autonomously, 68% assuming results are commercially influenced, and 65% refusing to store payment details. These are concerns about delegating spending authority and exposing household consumption patterns, the kind that do not go away just because the technology improves.
But filtering requires no delegation. The user asks a question, the agent answers, the user decides. The criteria are machine-readable or they are invisible. Packaging design, brand origin story, and shelf position, none of these register inside a filter that needs documented certifications, structured nutritional attributes, and composition data. That behaviour is already at scale, and it does not require autonomous purchasing to reshape which products get considered.
The Kantar figure is the one I keep returning to. A product losing 20-40% of its selection probability because its attributes are not machine-readable is facing a structural disadvantage. Which raises two questions. What determines whether a product is legible to the filter? And who controls the infrastructure that makes legibility possible?
When machines shortlist, value migrates from persuasion to proof

Here is a useful test for a food brand right now: if an agent filtered your product tomorrow, would it find machine-readable proof of what you claim, or would it find a story on your packaging?
If the answer is a story, the product is structurally disadvantaged in agent-mediated commerce. Better creative does not help a product score inside a filter that requires documented certifications, structured nutritional attributes, provenance chain records, and composition assays. The selection penalty that the Kantar study documents is what that disadvantage looks like in practice.
I find it useful to think about the infrastructure that processes these structured inputs in three layers.
At the top sit the agent platforms: OpenAI, Perplexity, Anthropic, Amazon Rufus, Walmart Sparky, and Instacart Cart Assistant. This is the interface layer, the surface where consumers interact, and shortlists get assembled. It is the layer most commentary focuses on because it is visible, named, and contested at high valuations.
At the bottom sits upstream measurement: soil sensing, nutrient assays, spectroscopy, and satellite imagery. This layer generates raw data about what is in the soil, what is in the crop, and what environmental and agronomic conditions shaped the harvest.
In the middle is what I am calling the claims-and-verification layer: the infrastructure that takes upstream measurements and translates them into machine-readable claims that agent platforms can query. This layer spans product content syndication, supply chain traceability, standards frameworks like GS1’s Digital Product Passport standard, and scoring systems that translate attribute data into structured outputs. These are different entities serving different functions, but they share a structural role: they manufacture the legibility signal that agents consume.
Antony Yousefian has argued the directional case well in The End of Brand Trust and The End of the Impulse Buy: verification costs collapsing, brand equity eroding, the farmer and soil layer reclaiming value. I agree with that direction. What I want to sit with here is where value concentrates inside the verification economy once it arrives, and who gets excluded from it.
My working view is that the translation step is where pricing power is most likely to sit, because it is the step neither the agent platforms nor the farms can fully own on their own. Platforms need verification but have incentives to commoditise it. Farms generate data, but most lack the aggregation infrastructure to translate it into agent-readable claims at scale, whether due to fragmentation, heterogeneous data formats, or the cost of standardisation across operations.
That is the clean version of the proof economy: quality that can prove itself gets rewarded, and the translation layer captures margin for making the proof legible. But three forces complicate the picture, and each one tilts the proof-equals-access equation in a different direction.
Three forces shift the proof-equals-access equation

1. Agent monetisation turns the shortlist into an advertising surface
The parallel I keep reaching for is SEO. In the early years of search, the dominant assumption was that good content, accurately indexed, would surface organically. Paid search gradually displaced organic results in most high-commercial-intent categories, and what emerged was a two-tier system where relevance determined eligibility and spend increasingly determined position within the eligible set.
Agent commerce is building a similar infrastructure. Stripe’s Shared Payment Tokens let agents pass scoped payment credentials to merchants. OpenAI introduced Instant Checkout in ChatGPT, then shifted toward directing shoppers to merchant storefronts, with Shopify building its own agentic storefront offering. Instacart’s Cart Assistant runs on the same commerce stack that underpins Instacart’s retail media business. Walmart Sparky now operates inside the Walmart app, ChatGPT, and Gemini, with checkout kept on Walmart’s own rails.
An agent monetised through retailer ad networks and platform revenue shares may not function as a neutral representative of the consumer’s dietary intent. Its shortlist would reflect some equilibrium between consumer preferences and platform economics, optimising for health within the constraints of whoever is paying for the infrastructure. That is a different dynamic from the rational health-optimiser that some of the more optimistic commentary assumes.
Machine-legibility gets a product into the eligible set. If agent commerce follows the search pattern, the position within that set will increasingly reflect spend.
2. Whoever defines “healthy” controls the filter
When a user tells an agent “keep it healthy” or “low-inflammatory,” a translation has to happen. The natural-language instruction must map onto filter criteria applied to a product database. That mapping is unlikely to be neutral, and the entity that controls it shapes the outcome for the products downstream.
The FDA finalised an updated “healthy” nutrient content claim in December 2024, its first revision since 1994. It is a labelling standard. It is not a product-level scoring API that an agent can query in real time. When an agent operationalises “keep it healthy,” it queries whichever database has already done that translation work.
A handful of private systems have built that translation layer, and they do not all agree on what “healthy” means. Yuka scores products with nutritional quality weighted at 60%, additive content at 30%, and organic status at 10%. Open Food Facts uses Nutri-Score, scoring on a nutrient-only basis. HowGood is primarily a sustainability intelligence company, scoring on eight environmental and social metrics and integrating Nutri-Score separately for nutritional context. Personalised nutrition apps like Zoe score the same product differently for different users, calibrated to individual metabolic response.
Take a full-fat organic yoghurt with no additives. It scores well on Yuka (nutrition plus clean ingredients), variably on Zoe (depends on the user’s metabolic profile), and differently again on HowGood (depends on the sustainability footprint of its supply chain). An agent shortlist filtered for “healthy” produces different results depending on which system it queries, and the consumer has no visibility into which taxonomy shaped the shortlist.
The analogy that keeps pulling me is pharmacy formulary placement. In pharmaceutical distribution, a drug’s presence on a formulary often determines patient access more directly than its clinical profile. The formulary decision happens upstream of the prescription. In agent-mediated food commerce, the taxonomy endorsement happens upstream of the shortlist. A product’s presence in the scoring system of a given platform's queries may matter more to its agent-era visibility than its placement on any retailer’s digital shelf.
3. Platform fragmentation multiplies the legibility target
The optimistic version of this transition assumes interoperability: one proof layer, universal reach. That assumption is not holding up.
Last month, U.S. District Judge Maxine Chesney granted Amazon a preliminary injunction blocking Perplexity’s Comet browser agent from accessing password-protected areas of Amazon, including logged-in Prime experiences. A brand’s presence inside an authenticated Amazon shopping flow, the one with rich personalisation data, is not addressable by agents operating outside Amazon’s perimeter. The emerging protocol standards reinforce the pattern. OpenAI’s Agentic Commerce Protocol and Google’s Agent Payments Protocol (AP2) each require separate integration work, and neither is emerging as a universal standard.
In Southeast Asia, Google and Sea Limited announced a partnership to build an agentic shopping prototype for Shopee, which holds 52% of the region’s e-commerce market, and to pilot agentic payments through AP2 via Sea’s fintech arm Monee. That is yet another platform-specific integration a food brand would need to reach agent-mediated shoppers in a different region.
For a mid-sized food brand trying to be legible to agents, this means the target is not one data standard but several, each with its own integration cost and taxonomy. Machine-legibility is not a single investment. It is one investment per platform that maintains a walled experience layer.
Fragmentation also resolves a structural question I raised earlier: whether the claims-and-verification layer retains independent leverage or gets absorbed by platforms. If every platform maintained the same taxonomy, a single acquisition could internalise the middle layer’s margin. In a fragmented environment, no single acquisition gives a platform full coverage. The middle layer retains leverage because it is the translation infrastructure between incompatible systems. The more fragmented the protocol landscape stays, the more durable the middle layer’s independent pricing power.
Taken together, these three forces mean the legibility economy is not a clean meritocracy where proof equals access. Access depends on proof, position within the eligible set reflects spend, and the definition of proof depends on which taxonomy the agent queries.
The proof economy’s cost floor determines who participates

Even setting aside monetisation, definitional politics, and fragmentation, the basic economics of producing machine-verifiable evidence sort food producers by scale.
Certifications, provenance chain documentation, composition assays, soil health records, nutrient density measurements: these are the attributes that move a product from invisible to eligible in agent-mediated shortlists. Supplying verifiable evidence is the new table stakes for commercial relevance.
The unit economics do not distribute evenly. A soil assay at agronomic resolution has a cost. Spectroscopy-based nutrient analysis at the lot or batch level has a cost. Third-party certification audits also have a cost. Building the data systems that retailer traceability mandates and GFSI-level food safety programs increasingly require its own investment.
The EU’s Ecodesign for Sustainable Products Regulation (ESPR), which introduces Digital Product Passports for priority sectors like textiles and batteries first, signals where food and agricultural products are likely headed next. At scale, the per-unit cost of all this is manageable. At five acres, it may exceed the margin the producer is working with.
The consequence is a sorting mechanism embedded in the proof economy’s structure. Mid-sized producers with the operational capacity to implement sensing infrastructure and the volume to amortise it gain access to agent-mediated shortlists. Artisanal and small-scale producers, the kind of long-tail supply that specialty food brands and farm-to-table operators have built sourcing differentiation around, face a proof layer that is technically accessible but economically out of reach at current cost structures.
Where this thesis might be ahead of itself
If sensing costs follow the trajectory of other AI-adjacent hardware, falling significantly per cycle as compute and miniaturisation improve, the cost floor argument may be temporary. The distributional effects I describe could be a transitional feature of early infrastructure rather than a permanent structural condition.
If platforms consolidate around a single protocol, with GS1’s Digital Product Passport being the most plausible candidate, fragmentation collapses and the middle layer’s pricing power weakens. A unified standard would simplify legibility into a single investment rather than one per platform, which is better for producers but changes the value map I have outlined.
And if agent monetisation evolves toward subscription models rather than advertising, the shortlist may stay closer to consumer intent than the SEO parallel suggests. The search pattern is one possible outcome, and it may not be the dominant one.
The direction of the shift, from persuasion to proof, is clear to me. The speed, the severity of the distributional effects, and whether the cost floor proves durable or temporary are the open questions.
What this means for you

Every food brand needs a legibility audit before agents run one for them
The diagnostic question I posed earlier in this piece, whether an agent would find machine-readable proof or a story on your packaging, is worth turning into an exercise.
Work through it: what structured nutritional attributes does your product have in queryable databases? Which scoring taxonomies (Yuka, HowGood, Nutri-Score) can access those attributes? Which agent platforms can see your product data inside authenticated environments? This is not a five-year planning horizon. The filtering is already happening.
The most defensible infrastructure plays sit in multi-protocol translation
For investors evaluating data infrastructure in this space, the fragmentation argument implies a specific thesis. The most defensible companies are those whose value increases with fragmentation: multi-protocol translation capability, cross-platform data syndication, taxonomy interoperability.
These companies survive consolidation (they become the acquired integration layer) and thrive during fragmentation (they are the only path to multi-platform legibility). This is a different filter from “invest in the agent platforms” or “invest in the sensing layer,” both of which face commoditisation pressure from different directions.
Whether legibility becomes a public utility determines who participates
The cost floor and the definitional politics I have described will not self-correct through market dynamics alone. Three interventions would change the distributional math: cooperative data infrastructure that lets small producers pool sensing and certification costs across shared operations, public scoring standards that prevent private taxonomies from becoming the sole gatekeepers of “healthy” or “sustainable,” and protocol-level interoperability mandates that reduce the per-platform cost of legibility.
These are policy choices, and they need to be made before the architecture hardens. The sector needs to decide whether legibility is a public utility or a private good. That decision will shape whether the proof economy creates a more open food system or reproduces the concentration dynamics of the shelf-space era in a new form.
If you found value in this newsletter, consider sharing it with a friend who might benefit from it!
Or, if someone forwarded this to you, consider subscribing.
Disclaimer: The views and opinions expressed in this newsletter are my own and do not reflect those of my employer, affiliates, or any organisations I am associated with.
Such a good piece!